Originally posted on Archetype Mirror
Written by Nick Pai, Katie Chiou
At Archetype, we believe that understanding where new interoperability projects are positioned within the infrastructure stack is crucial to making sound investment decisions. The technical stack for blockchain infrastructure has changed drastically over the years, demanding that frameworks for understanding interoperability adjust as well.
With this post, we want to reflect on the evolution of the blockchain interoperability stack, unpack each of its components, and share our mental model for thinking about what comes next.
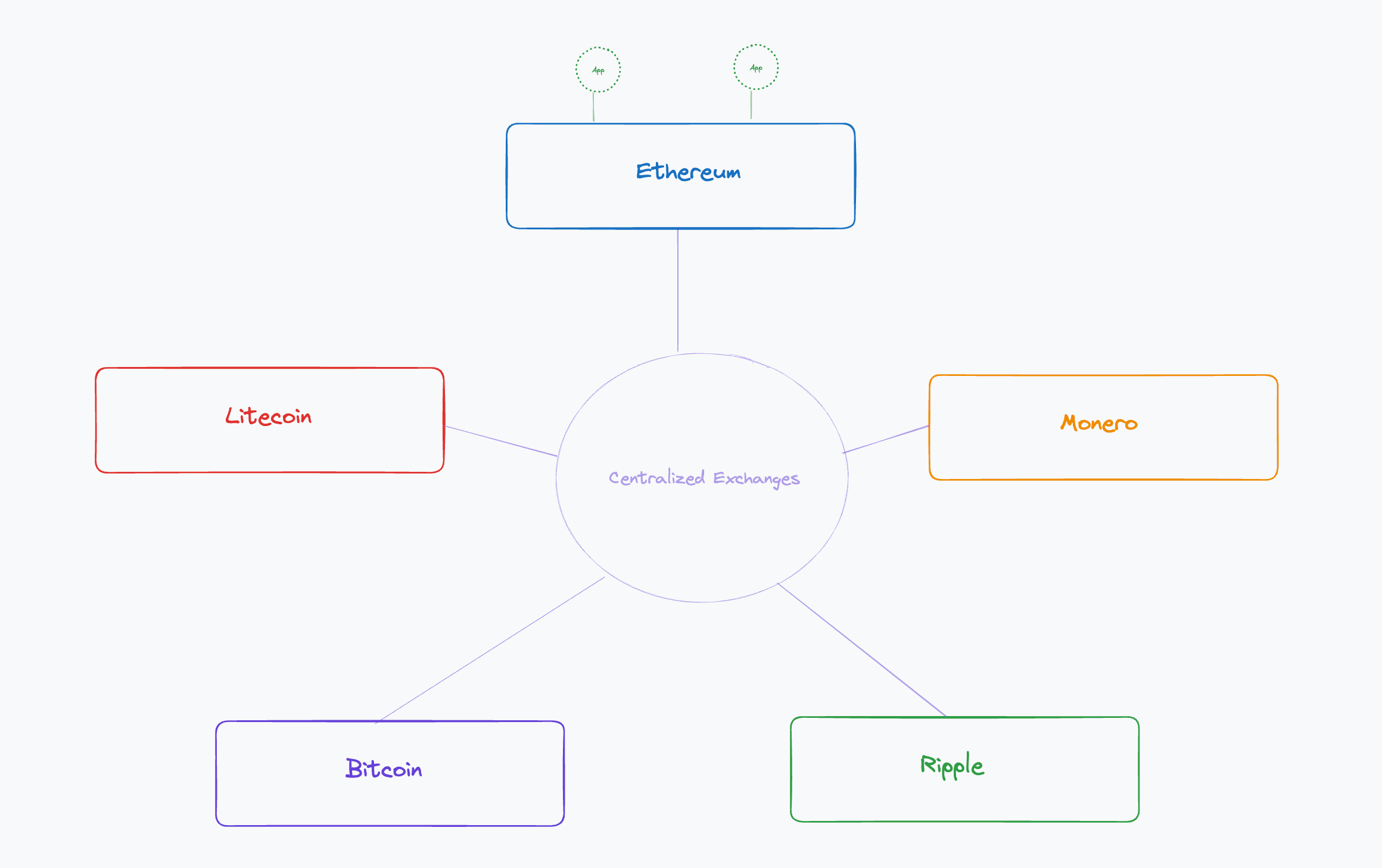
Native Layer 1s
Native Layer 1s (L1s): In 2017, the blockchain landscape consisted of isolated chains that could only be connected somewhat through centralized exchanges (CEX) as hubs.
“Alt” L1s: As Ethereum gained market share, it became table stakes for other blockchains to have native bridges to Ethereum, rather than having to always go through a CEX. These connections helped bolster Ethereum’s dominance over other chains even further, creating the “Alt L1” narrative.
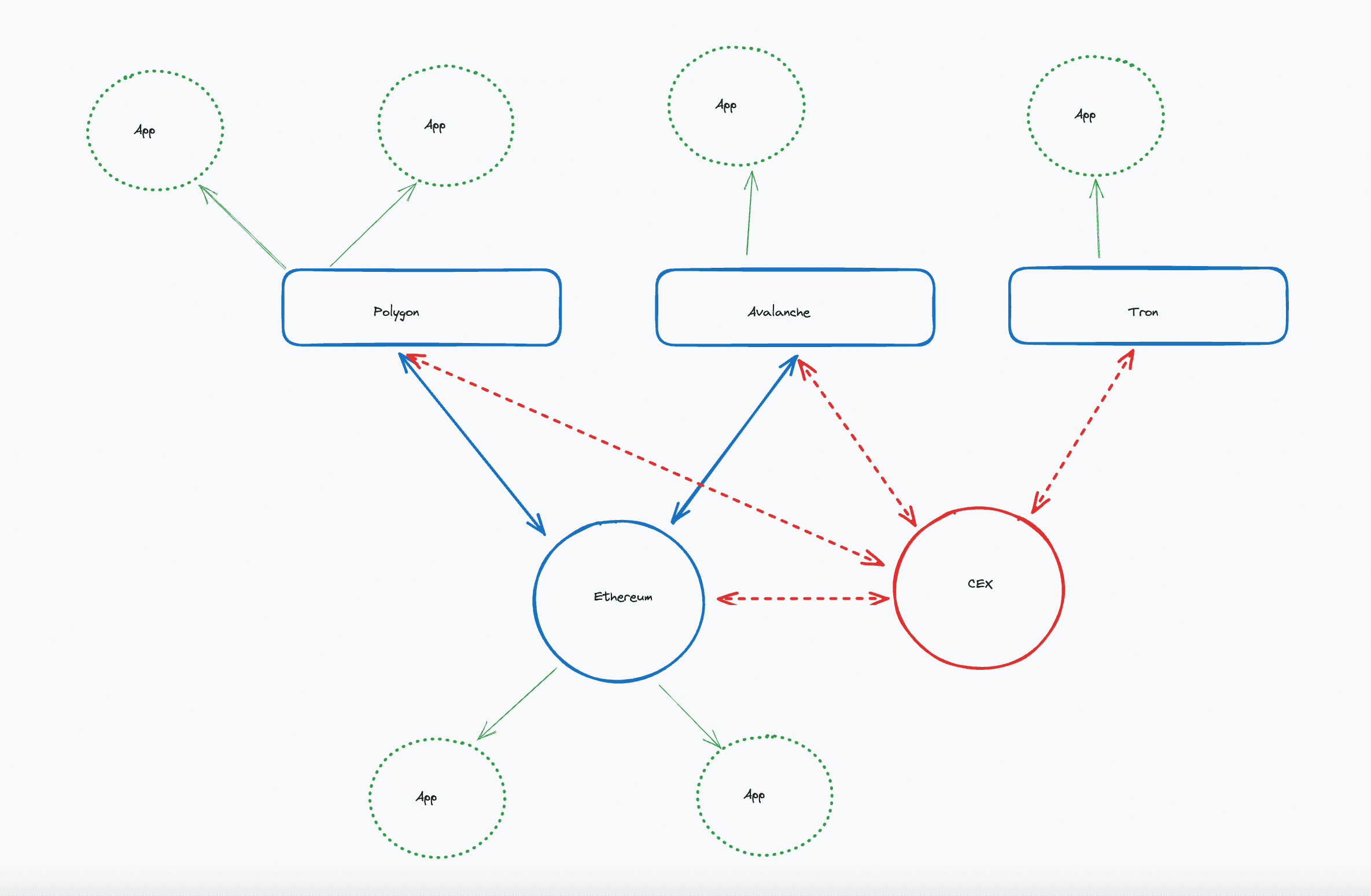
"Alt" Layer 1s
Layer 2 (L2)-centric: The next evolutionary step saw new networks that not only connected to Ethereum but used it as a data availability layer. These networks, like Arbitrum and Optimism, offered an enhanced UX to end users without trading security, because they used Ethereum as their settlement layer. Naturally they were called “Ethereum L2s” or rollups.
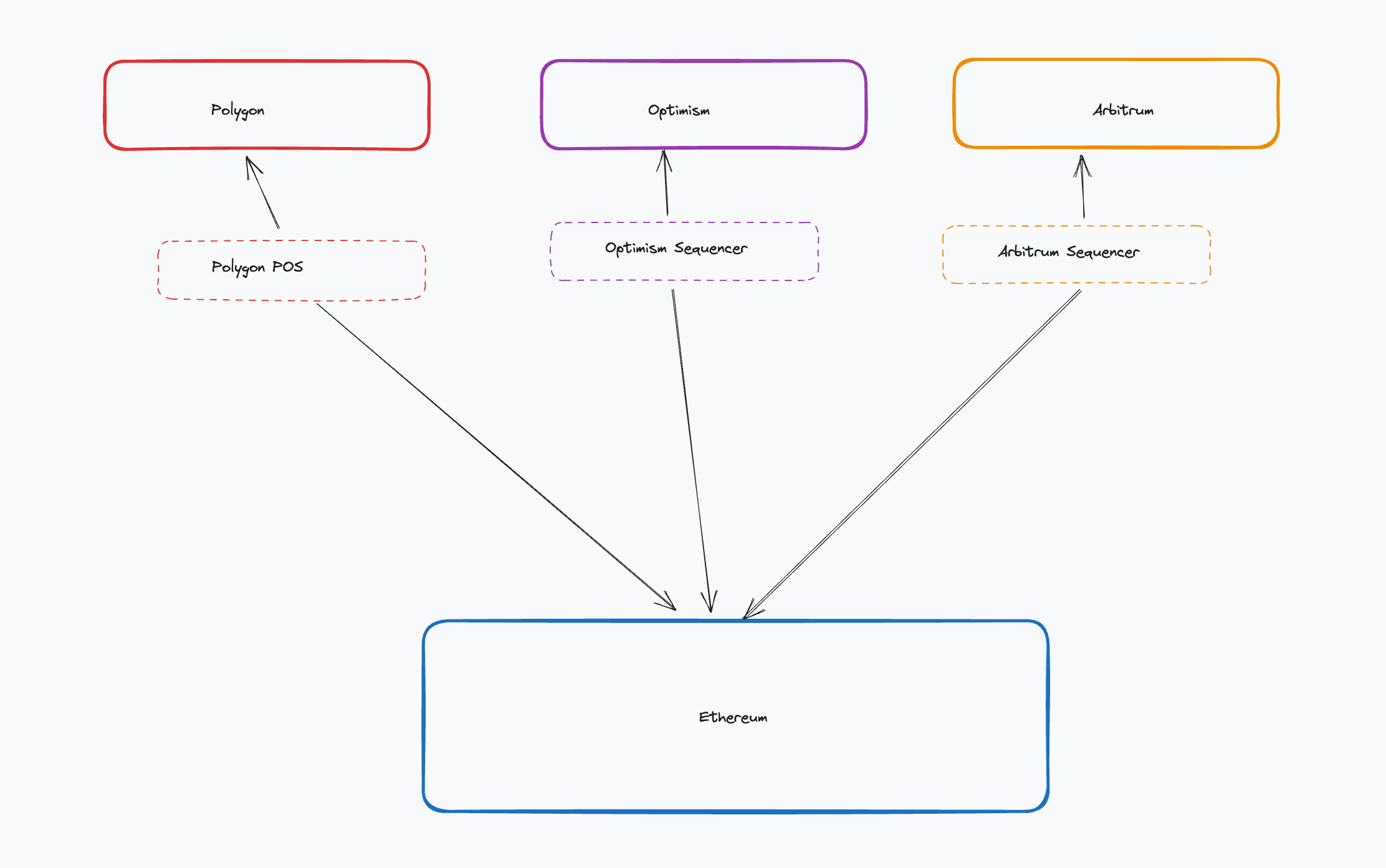
Layer 2-centric
This brings us to today, where L2s have gained a lot of momentum, the Ethereum roadmap is “rollup-centric,” and there are now connections between each of the L2s, a big step from the state of blockchain infrastructure five years ago where there was a handful of independently-secured blockchains that were only connected by CEXs.
Today, the design questions around blockchain interoperability are generally constructed around the following factors:
-
L2s that offer very fast and cheap UX
-
L2s and L3s (appchains) serving as the home to new user applications
-
More chains leveraging shared security and infrastructure
-
A focus towards communication between L2 chains rather than just L1 to L2 chains
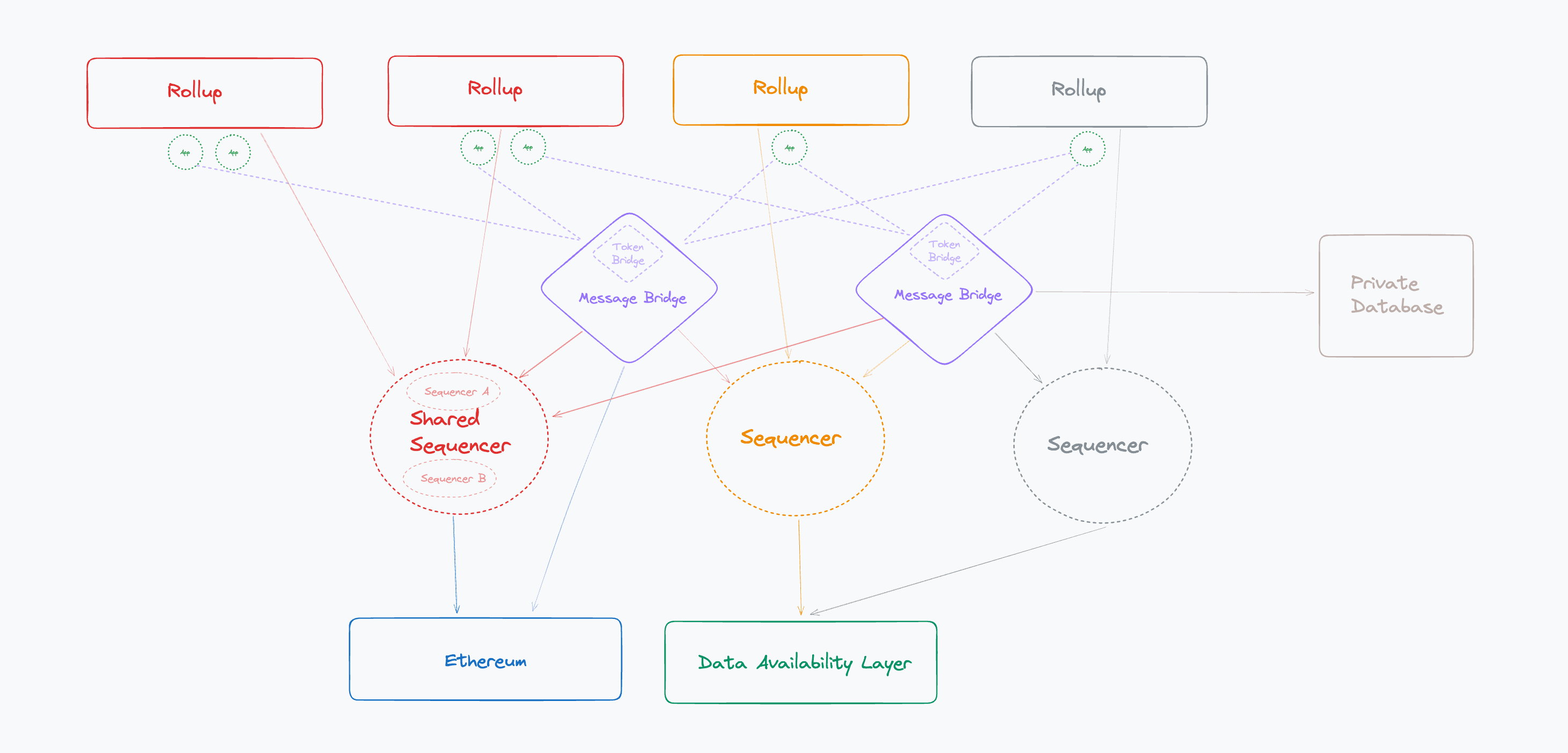
The future?
The number of connections between blockchains has created a lot more obscurity for people who want to better understand how everything works.
How do my tokens transfer from L2 to L2?
Who is securing my data, and who am I implicitly trusting to keep my data safe?
To answer these questions, we need to understand each layer of the stack.
What we’re going to cover:
-
L2s
-
Why are L2s fast and cheap and how are they secured
-
The relationship between L2 and Ethereum (L1)
-
The relationship between L2s and Data Availability (DA) layers
-
-
Sequencers
-
What is a sequencer
-
Shared sequencers
-
-
Fraud Proofs, Validity Proofs, and Proof of Authority (PoA)
-
Bridges
-
Types of bridges
-
Bridges vs sequencers
-
-
Intents
-
What are intents
-
Intents vs bridges
-
-
CEXs and DEXs
Let’s dive in.
Layer 2s
Users interact with dApps, and users demand that those dApps are fast and cheap, which is why dApps today are often deployed on L2s like Polygon, Arbitrum, and Optimism, and not on Ethereum.
Why are L2s cheaper than L1s?
L2s process transactions offchain and periodically publish batches of finalized transactions to some onchain layer that ensures the data was in fact published and made available to verify (data availability). The reason why L2s can be so fast is that they record user interactions offchain on a private server, offering a “web2” experience. In the background, L2s publish batches of these transactions to a data availability layer, offering additional transparency and security.
How do L2s publish and store transaction data/history today?
Choosing a secure data availability layer is the most important security decision an L2 makes. If an L2 is an “Ethereum Rollup,” then it publishes its transaction data to Ethereum.
There are two reasons to choose Ethereum. First, Ethereum is the “most immutable” layer. Once a rollup posts transaction data to Ethereum, it is infeasibly expensive to reverse finality on Ethereum. So, L2s can publish their state to Ethereum and have a very high degree of confidence (following Ethereum’s finality period of ~13 minutes or 2 epochs of 32 slots taking 12 seconds each) that their transaction will not be removed. The second reason is Ethereum’s high availability of data. Ethereum has a large number of nodes replicating and verifying transaction data, making it highly unlikely that data would ever disappear or be entirely unavailable.
However, using Ethereum for data availability is famously expensive. While Ethereum is generally the most secure data availability layer, it wasn’t optimized to just store data—it’s a generalized computing machine.
Until EIP4844 is implemented, there is no way to request blockspace only; you have to pay the same gas as everyone else sending normal transactions on Ethereum. So if an L2 chooses to publish state on Ethereum, it’s choosing the blue chip option but it’s also paying a premium for its security.
What options are available to an L2 that wants to pay less to post state? Enter the DA layer.
Data Availability (DA) layers like Celestia are optimized to offer a place specifically for data availability, where demand for blockspace is lower and blockspace itself is cheaper.
The natural downside is that newer DA layers are less economically secure than Ethereum at launch, given the necessity and time needed to bootstrap a network. Another downside to a pure DA layer like Celestia is that you can’t naturally do computation on the data, which adds a layer of complexity when arbitrating or validating proofs. When sending a transaction on an L2, you should be asking: Which DA layer does this L2 publish its state to, do I trust it, and how can I later access that data?
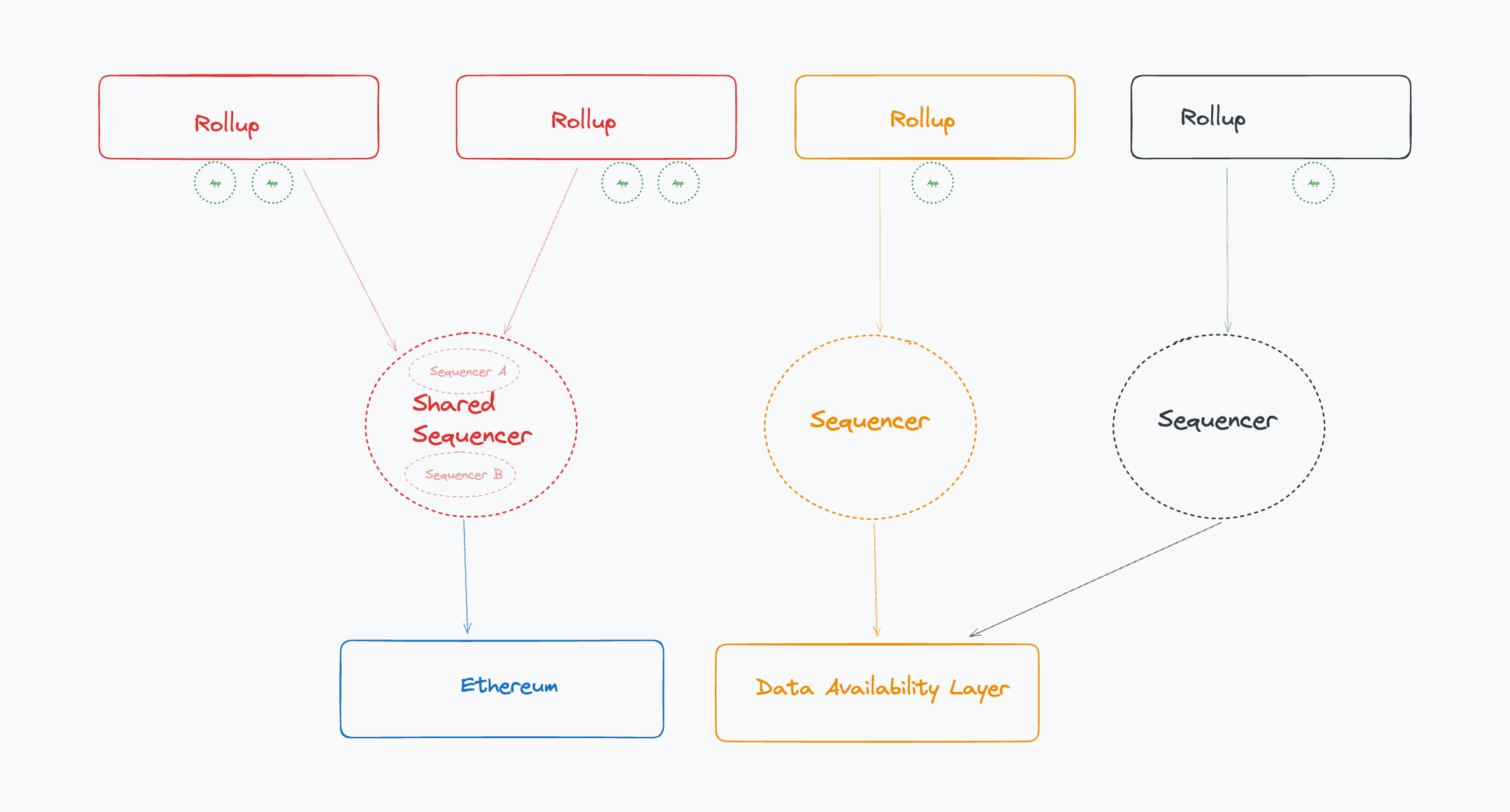
Modular DA layer
Why do L2s pay to post data?
Posting state on an external DA layer removes a centralization vector for L2s insofar as it allows for permissionless, independent verification of state. In the case of optimistic rollups, data availability is needed to generate fraud proofs. In the case of ZK rollups, data availability is needed to ensure censorship resistance and liveness.
If an L2 never published its state onchain publicly, then it would just be in a private server. Users would be at the complete mercy of the L2 operator, which also introduces questions around liveness (what if the centralized operator goes offline?).
If the L2 publishes its state to a chain that is relatively insecure, then users would also be at the mercy of that chain. For example, if L2s posted their history snapshots to Tron, then Justin Sun would have the ability to change the L2’s history.
This is why most L2s choose to publish state to highly secure and battle-tested chains like Ethereum. Users want to know that they have control of their data and that their transactions won’t be modified or reversed.
A key point worth repeating: An L2 is only as secure as the DA layer/L1 that it publishes state to.
Rollups without DA:

Does that mean that DA layers are competitive with Ethereum?
They compete for blobs of data; post-EIP4844, these DA layers will compete directly with the Ethereum “Blob” market.
For other types of transactions like sending tokens or interacting with DeFi apps, Ethereum competes with other turing-complete blockchains like Solana, BSC, and Avalanche that don’t publish their state to Ethereum.
Sequencers
What is a Sequencer?
Sequencers are the parties that actually publish L2 state to the DA layer. They are in charge of determining the canonical order of transactions on an L2 and publishing snapshots of that history to a DA layer. Sequencers pay the DA layer fees to post the data, and sequencers earn revenue by collecting all fees paid by users who send transactions on the L2s. Sequencers can be single, whitelisted parties, or they can be competitors in a decentralized market vying to publish the next set of L2 state. Typically, sequencers needs to be aware of:
-
State on the DA layer so that it can publish data to it/mint bridged assets (if the DA layer supports smart contracts
-
State on the L2 layer so that it can sequence the L2 transactions
Most of these dynamics assume that the sequencer is also a block builder (which is true of sequencers in production today), but these roles could be decoupled depending on design/development around decentralized sequencers, shared sequencers, and PBS
What is a Shared Sequencer?
Generally speaking, proposals for shared sequencers today separate transaction ordering and execution; shared sequencers don’t execute transactions. This design decision makes shared sequencers scalable–they’re fast, sequencer node requirements are light because ordering is stateless, and it becomes relatively easier to decentralize the sequencer set.
However, because these sequencers don’t execute transactions, this places a centralizing force on block builders–the parties that actually execute the state transitions across the connected domains. The more rollups connect to shared sequencing layers, the higher requirements that are needed for builders to be competitive across domains. The higher the resource requirements, the risks of centralization at the builder level. The design space around decentralized block building and proposer-builder separation is vast and for sake of scope will not go down that rabbit hole here.
Another issue: shared sequencers alone don’t offer cross-rollup atomic conditional transaction execution.
For example, a common demand is for a user to bridge tokens from Optimism to Arbitrum and then swap tokens on Arbitrum. Ideally the user would want both of these actions to execute in order, or none at all. In the worst case, the user would end up with tokens on Arbitrum that are not swapped.
To enable this conditional execution for transactions between rollups A and B, a shared sequencer would need to sequence both A and B and publish a shared L2 state to a DA layer containing both conditional transactions.
This is likely where the shared sequencer evolution will go next: interdependent L2 state secured by either “shared fraud proofs” or ZKPs. To get there, shared sequencer behavior and system contracts will have to change to support publishing multiple L2 states in a single L1 transaction.
Prediction: If shared sequencing becomes the dominant paradigm over single sequencing, then state validity between L2s using a shared sequencer will be interdependent.
Here is an interesting proposal introducing this concept of “shared fraud proofs,” and here’s another recent article expounding on tradeoffs in running a sequencer.

Another potential concern around shared sequencers is that teams utilizing shared sequencer networks may lose control over certain operational parameters and value capture opportunities. For example, shared sequencers could extract intra-rollup MEV that would have been valuable to the rollup itself. Given that this would be an obvious race to the bottom in the shared sequencer market, the higher likelihood is that shared sequencers will focus on extracting inter-rollup MEV that wouldn’t have been as easily accessible to individual rollups anyway.

We’ve established that an L2 should post its data somewhere transparent, but how do we verify the data?
If whatever data the L2 sequencer publishes to L1 is considered valid, then what prevents the L2 sequencer from posting an incorrect snapshot of the L2 history? Couldn’t the sequencer pay themselves a little bit extra ETH out of user wallets?
Fraud Proofs
In optimistic rollups, L2 state is published optimistically and is not considered final until it passes through a challenge window (e.g. a 7 day challenge window). During this challenge window, anyone can dispute an L2 state commitment if they believe that the commitment is missing the correct transaction history. To submit a dispute, one must publish a fraud proof that is used in an interactive process to resolve the dispute.
The main advantage of fraud proofs is that they only need to be generated when there is a dispute.
Validity Proofs
A validity proof claims that the L2 state is valid and proves it at the time of publishing. There is no dispute window; if the proof is verified by an L1 contract designed to verify such proofs, then the L2 state is valid.
The main advantage of proving L2 state via validity proofs is that the L2 state published to L1 can achieve immediate finality. This means that L1 contracts can instantly take the L2 state as “final” and act upon it. This is why L2 to L1 withdrawals for ZK Rollups are very fast (~24 hours), compared to the 7 day challenge window for optimistic rollups.
Proof of Authority (PoA)
The last way of validating L2 state is through a Proof of Authority (PoA) mechanism. This is when the sequencer publishing the L2 state basically is given the authority to claim: “This is valid because I am publishing it.” This is how many rollups work in practice today; sequencers run permissioned full rollup nodes that validate state via PoA.There are no challenge windows, there are no proofs. Users simply trust these sequencers to not modify the L2 state.
How do fraud and validity proofs actually work?
These proofs are very difficult to implement and expensive to verify. They essentially require simulating the L2 VM execution for a set of alleged L2 transactions and an initial state. If the resulting state that is produced following those alleged transactions on the initial state differs from what the sequencer published to L1, then the state is disputable.
These proofs must be verified on the same DA layer that the L2 state is published to, which makes their verification expensive to run.
The main tradeoffs between fraud and validity proofs:
-
Cost to Validate Proof: Validity proofs are generally much more expensive than fraud proofs.
-
Speed: Fraud proofs use a Dispute Time Delay (DTD) system–the challenge window–meaning transactions don’t reach finality on L1 until the window passes, whereas validity proofs are verified immediately in a single transaction.
-
Implementation Complexity: Both types of proof verification contracts are difficult to build. Validity proofs rely more on the succinctness property of cryptographic tools so that they can simulate L2 state in a single transaction. Fraud proofs are interactive and therefore require fewer cryptographic tools but more offchain infrastructure is needed to support an interactive proving system.
-
L2 VM Implementation complexity: L2 state that is validated via validity proofs usually requires a modification to the EVM in order to make the validity proof verification cheaper. L2 state validated by fraud proofs can more easily mirror the EVM exactly.
-
Running Cost for Sequencer: Validity proofs require a payment for each submission to L1 while fraud proofs only impose costs when a challenge is submitted. In the case that a challenge is submitted, however, fraud proofs require payment for every interaction between the parties arbitrating the dispute (interactive), whereas each validity proof is generated in a single transaction (non-interactive).
-
Upper Limit on Funds at Risk: If a fraudulent sequencer is not disputed, all L2 funds are at risk. If a sequencer does not submit a valid validity proof, then the L2 state is effectively frozen but no funds are lost.
-
Operating Cost for Validators: In a fraud proof system, there should always be at least one honest validator watching the sequencer’s submissions. In a validity proof system, there is no need for external validators assuming the validity proof is submitted
It’s worth noting that there are designs for non-interactive fraud proofs in development, though more technically challenging to implement.
There is a lot more to dive into on this topic. We find these resources particularly helpful:
Bridges
Before diving into specific examples, it’s worth teasing out subtle differences between how bridges are discussed in different contexts.
An arbitrary message bridge (AMB) is a protocol that keeps track of arbitrary cross-chain state—arbitrary meaning anything from token transfers to data storage to anything else. Even more simply, message bridges essentially make state from one chain available on another chain. (This sounds a lot like a shared sequencer.)
Diving into the mechanisms by which bridges are validated/secured is out of scope for this post, important to understand. A few resources that may be helpful can be found here and here (DYOR!)
A token bridge is an application of a message bridge that uses the cross-chain state to transfer assets/capital between chains.
For example, if the token bridge sees that transaction A, a 10 ETH “burn” has happened on Optimism, then it instructs a contract on Arbitrum to release 10 ETH to the user. If the 10 ETH burn gets wiped from history, then the token bridge is likely held liable for this loss. A token bridge is built on top of a message bridge because it needs to be aware of state on both origin and destination chain and also needs to know when transactions get finalized on the origin chain before it acts on the destination chain.
The safest, albeit slowest, way to move assets between L2s is to withdraw via the origin L2’s canonical token bridge to the L1 and then deposit from L1 to the destination L2 via that L2’s own canonical token bridge. Using a canonical token bridge is often a slow process as it’s dependent on withdrawing from an L2 to L1.
A “canonical token bridge” is essentially a special service offered by L2 sequencers. Depositing to an L2 via the canonical token bridge means locking funds on a sequencer’s contract on L1 and requesting that the L2 sequencer mint an equivalent amount of funds on the L2 chain.
Withdrawing from an L2 requires sending funds to a special contract on the L2 to be “burned” and waiting for the sequencer to publish proof of this burn to L1. Once that proof is confirmed, like any other L2 state published by the sequencer to the L1, the sequencer’s L1 contract can release tokens to the user.
Using the canonical token bridge is as slow as waiting for the rollup full nodes to finalize L2 state on L1, but it’s also as “safe” as it gets when interacting with the L2.
A faster way to transfer assets between L2s is to use a fast bridge. A fast bridge temporarily custodies your capital on a non-sequencer contract that then fronts you your capital on a destination chain. This means that the user is temporarily placing trust in the fast bridge to not modify their information or steal their funds.
How fast bridges work:
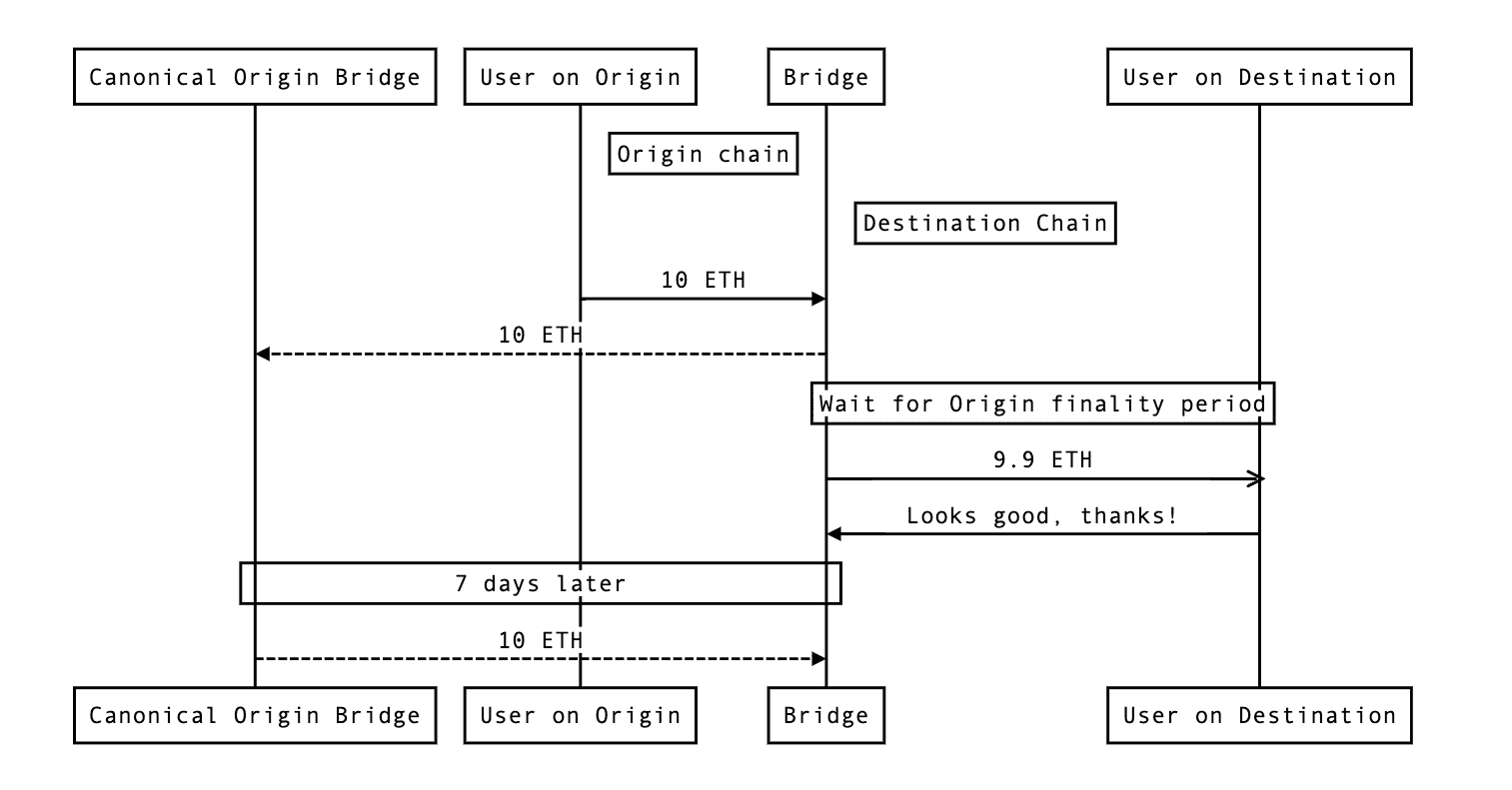
The diagram above shows the flow of funds that enable the user to receive their funds quickly, the fees that the bridge earns for providing the fast bridge service, and the finality risk that the bridge assumes for the user.
First of all, fast bridges credit users their bridged amount minus fees on their desired destination chain. In this case, this is 10 ETH minus a 0.1 ETH fee. The user walks away happy to have received their expected amount of funds so quickly.
Let’s pretend that the bridge prefers to custody assets on Ethereum. So, unbeknownst to the user, the bridge protocol will withdraw the user’s deposit via the slower canonical bridge to Ethereum. Once the canonical bridge withdrawal finalizes (e.g. seven days later in the diagram above), the bridge protocol has ended up with a fee surplus of 0.1 ETH on Ethereum (10 ETH user deposit minus 9.9 ETH credited to the user).
In exchange for getting paid for this service, the bridge assumes the finality risk of the user’s deposit: If the user deposit is reverted by the origin chain’s sequencer any time during the seven day finality period, then the bridge will lose funds. This is because the bridge has already credited user funds on the destination chain but will no longer receive the user’s original deposit via the canonical bridge.
Bridges vs Sequencers
How can users be assured that if they deposit 10 ETH on the origin chain that they’ll receive 10 ETH on the destination chain (minus fees)? This boils down to that respective bridge’s security mechanism, which we’ll see looks eerily similar to a sequencer’s security mechanism.
When the bridge credits funds to the user on the destination chain, the user needs a way to verify that the bridged funds were correctly received. Ideally, the bridge also offers a recourse option in the case of an error. One way the bridge can offer this assurance is to allow the user to challenge the bridge in a challenge window. Much like the fraud proof process, this allows users to take their security into their own hands and provide proof of fraud in the case that they never received their funds as expected. This is why it’s important that the bridge publish its transaction history to an immutable DA layer—to offer transparency to users and assure them that if they do ever challenge the bridge, that the bridge cannot modify its history and must correct the error.
So it should be apparent now that both fast bridges and sequencers require DA layers in order to give users confidence that they are processing transactions honestly.
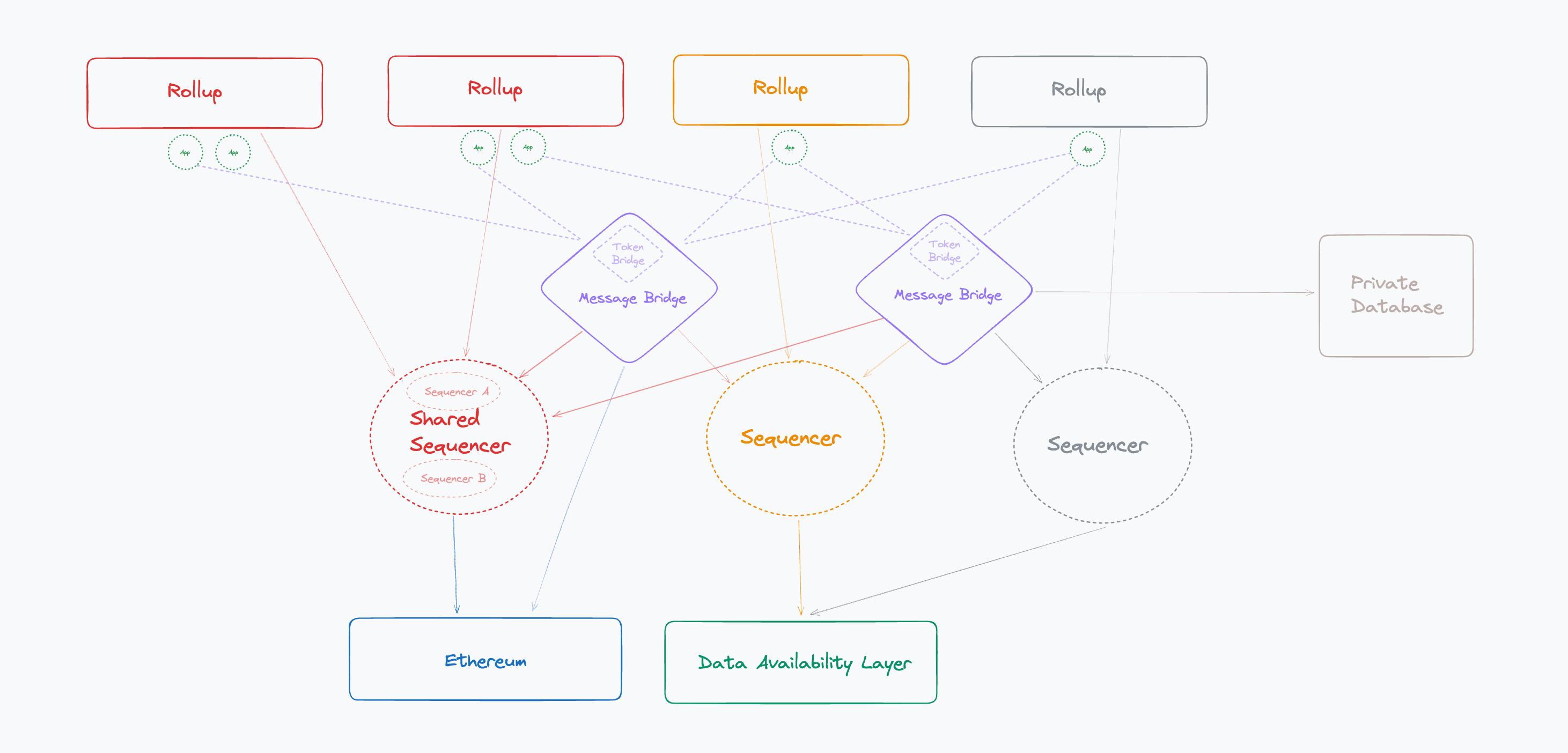
A bridge is only as secure as the DA layer that it posts state to and its dispute mechanism.
These fast bridges serve as a way to provide economic atomicity to users without technical atomicity. If users could express their preference to execute a transaction on one rollup and conditional on another transaction on another, and is only willing to pay if both of these conditions are met, by providing these economic incentives fast bridges give users the properties of technical atomicity by outsourcing the execution of that to specialized parties in the absence of some actual communication or shared sequencing layer between different rollups.
ZK Bridges
Bridges can also offer security assurances to users by accompanying messages published to the destination chain with validity proofs. These types of bridges are called ZK bridges. The destination chain requires a contract to be deployed that can simulate the origin chain’s consensus and can verify that an event happened as claimed on the origin chain. The validity proof is used as input into this verification contract to prove to the contract that the message sent to the destination chain is an accurate representation of the request sent on the origin chain.
Of course, bridges can also use PoA if they don’t want to publish data anywhere transparently and immutably.
Intents
An intent is a set of preferences that the user wants to be fulfilled including the destination chain(s) where they want those preferences fulfilled.
A marketplace for intents offers to store a canonical history of intents across one or more chains. An intent marketplace allows users to signal their preferences, relayers to fulfill those preferences, and offers validation for the fulfillment of those preferences. If a user feels that a relayer did not correctly fulfill their intent, then the intent marketplace should offer a way for the user to dispute or challenge the relayer.
This is starting to sound a lot like a bridge.
Intents vs Bridges
Intents are innovative because they open design space for a different, more flexible mechanisms/language for expressing and executing transactions.
An intent marketplace does not have to be cross-chain but it’s well-positioned to be, given it’s already defining a new paradigm and language for expressing preferences and storing a canonical history of intents.
Cross-chain intent marketplaces can therefore be thought of as a more specific form of general message bridging.
The Archetype team outlines specific examples of intent systems (SUAVE, Anoma) in a previous post here.
CEXs/DEXs
We began this post by reflecting on how, in what feels like eons ago in crypto time, CEXs were the main hub for crypto assets. Given all the evolution since then that we’ve just outlined, where do CEXs/DEXs fit into today’s framework?
CEXs essentially function like both dApps and token bridges insofar as you can use them as a way to transfer tokens from one network to another. You can almost think of CEXes as Proof of Authority bridges. The exchange offers little recourse for users in the case that it steals your funds. The main recourse is to challenge the CEX legally, in person. GLHF. DEXs that exist on a single chain are dApps. Cross-chain DEXs are like token bridges plus dApps.
Conclusion
Let’s revisit the full diagram of the model that we’ve built:
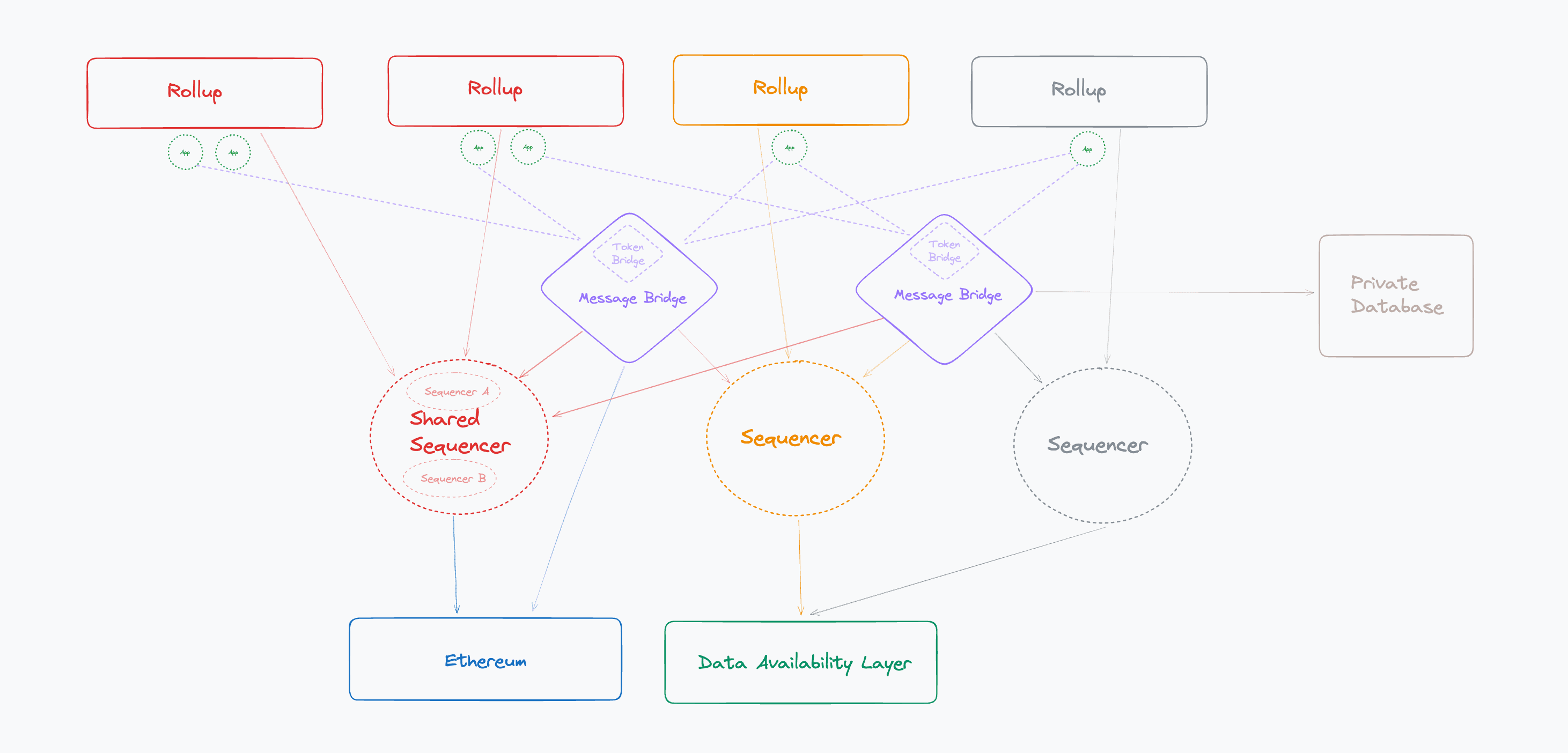
A few general observations:
-
Users interacting on L2s pay L2 sequencers
-
Users looking to jump across chains pay Fast Bridges (and L2 sequencers)
-
Bridges pay sequencers on the destination chain to carry out bridge activity
-
L2 sequencers pay DA layers to store data
-
Shared sequencers get first shot at extracting MEV between the L2s that they sequence Shared sequencers also get paid by multiple L2s and can reduce their costs by publishing both of the L2 states in a single, batched transaction to the DA layer
The blockchain interoperability stack has seen multiple iterations over the past several years, leaving trails of valuable takeaways for folks who have closely watched the space throughout history. Regardless of which cyclical buzz word you use (sequencers, bridges, and cross-chain intent marketplaces), interoperability infrastructure begins from the same first principle functions:
-
Ordering transactions canonically (whether single chain or across multiple chains)
-
Posting data to a transparent and immutable DA layer
-
Offering data proof/verification mechanisms
Keeping these principles in mind, we can ask better questions and better assess where value will accrue in the interoperability stacks of the future.

Thank you to @0xFunk, @mrice32, and @pumatheuma for thoughtful review and feedback on drafts of this post.
Disclaimer:
This post is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. You should consult your own advisers as to legal, business, tax, and other related matters concerning any investment or legal matters. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by Archetype. This post reflects the current opinions of the authors and is not made on behalf of Archetype or its affiliates and does not necessarily reflect the opinions of Archetype, its affiliates or individuals associated with Archetype. The opinions reflected herein are subject to change without being updated.